managers, workers, and the delegation model
Netsky works better when manager0 does less.
That sounds backward until the queue gets busy. The owner-facing manager is most useful when it turns input into durable work, hands bounded slices to the right actor, and keeps the return path legible. That is the delegation model Netsky is built around now.
The older clones are managers. clis are workers. post described an earlier boundary. This post is about the current DB-backed loop: an in-process agent runtime, named actors, task and actor rows, notes, and comms that make delegation recoverable instead of purely conversational.
sequenceDiagram
owner->>manager0: prompt
manager0->>meta: task row + note + routing
manager0->>managerN: coordination lane
manager0->>workerN: execution slice
managerN-->>manager0: outcome or blocker
workerN-->>manager0: result or blocker
manager0->>owner: terse answer + next
The shape is simple:
| actor | owns | use it when | primary artifact |
|---|---|---|---|
manager0 | owner-facing triage and final reply | the system needs queue shaping, delegation, and synthesis | manager_prompt(…) |
managerN | one bounded coordination lane | the work needs its own sub-queue, review loop, or handoff surface | start_manager(…) |
workerN | one concrete task slice | the job has a visible done condition and should stay narrow | start_worker(…) |
In practice, the routing question is short:
| if the work is… | send it to… | because… |
|---|---|---|
| owner-facing and ambiguous | manager0 | it needs triage and decomposition |
| bounded but multi-step | managerN | it needs coordination without blocking the top lane |
| specific and finishable | workerN | it needs execution, not more supervision |
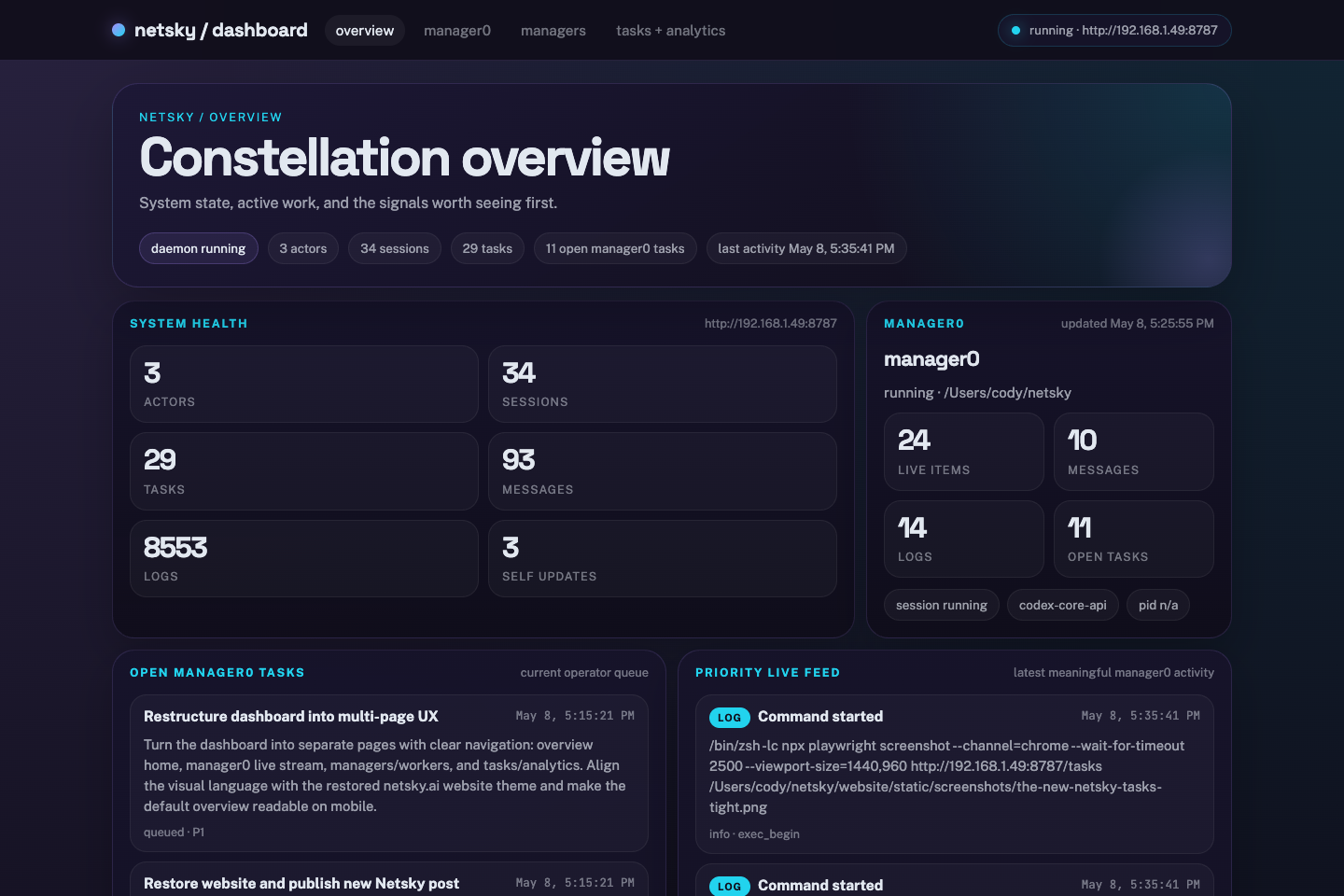
The live overview already shows the top of this model: manager0 at the center, open work below it, and recent delegated activity on the side.
manager0 is a delegator, not a sink #
The current manager prompt says the quiet part directly: keep manager0 clean for user input, break goals into DB tasks, delegate to workers and manager clones, and preserve durable notes. That is not style guidance around the system. It is part of the system.
That matters because a manager thread that tries to both coordinate everything and personally execute every slice turns into the same failure mode as a human bottleneck: too much context, too little throughput, and no clean handoff boundary.
That gives manager0 a narrower job:
- triage the next important work
- split work into bounded tasks
- choose whether a slice needs another manager or only a worker
- synthesize the return path back to the owner
That is why the public status view and /api/dashboard snapshot center on manager0 actor and session state, tasks owned by manager0, and recent manager0 messages and logs. It is the visible top of the delegation lane, not the only actor doing useful work.
what managers are for #
Starting a manager upserts a named coordination actor, ensures its session, sets cwd and prompt, and then submits the assigned objective when one is present.
That is the right tool when the problem is not just “run this one change” but “keep this lane moving.” That is a different claim from the older clone-era piece: the important boundary now is durable coordination, not just actor naming. A manager clone is useful when the work needs:
- multiple decisions instead of one edit
- its own sub-queue and notes
- parallel progress away from
manager0 - a clean place to hold a bounded objective for a while
Managers are coordinators, not just bigger workers. They exist so manager0 can hand off a lane without losing track of it.
what workers are for #
Workers are the opposite. They are supposed to be narrow.
Starting a worker creates a real task record, marks it in-progress, upserts both the manager and worker actors, and then submits the task text directly into the worker session. The worker prompt is simple on purpose: keep changes scoped, report blockers or completion through netsky comms send, and store durable context with netsky notes.
That is the useful split:
- managers own a coordination objective
- workers own a concrete slice
If the work can be phrased as one bounded task with a visible done condition, it should usually be a worker.
why the database matters here #
The delegation model only works because the queue is durable.
active_tasks_for_owner(...) lets the system recover the current open slice for a given actor. The schema migration defines the actor, session, task, message, note, and log tables, and the dashboard snapshot reads those same records back out for the web surface.
That means delegation is not only a prompt convention. It is backed by rows:
- who owns the task
- whether it is queued or in progress
- which actor is supposed to resume it
- what nearby notes and messages explain its state
Without that, “parallelization” is just several chats happening at once. With it, the system can explain who had the ball, why, and what should resume next.
what comes back up the chain #
Workers and manager clones do not reply directly to the owner. They report upward.
The worker prompt tells the actor to report blockers or completion to its manager through netsky comms send. The output routing code reflects the same hierarchy: workers route back to their manager, other manager actors route back toward manager0, and manager0 alone routes to the user.
That keeps the outside surface short. The owner should not need five parallel streams of implementation detail. The system can fan work out internally and still collapse the answer back into one terse reply.
the limit on parallelization #
More actors is not automatically better.
Parallelization helps when the work slices are genuinely independent and the return path is clear. It hurts when the slices are tightly coupled, underspecified, or all depend on the same immediate decision from manager0.
That is why the current model has shape:
manager0stays owner-facing- manager clones carry bounded coordination lanes
- workers execute narrow slices
- the database keeps the queue and handoffs durable
The point is not “spawn more agents.” The point is to keep the next useful actor boundary obvious.
That is the real change from the older clone-era framing. The interesting part is no longer that different actor types exist. It is that the work loop is durable enough to hand tasks across them cleanly.
When this model is working, the owner sees one concise thread, manager0 stays readable, managers hold coordination lanes open only where they help, and workers finish narrow slices without turning the whole system into one giant shared context window. That is the delegation model worth publishing: fewer heroic managers, clearer boundaries, and a queue that remembers what happened.